2022年振り返りと2023年の目標

お世話になっております。
4か月ぶりの更新になってしまいました。ここ最近機械学習コンペから離れているので更新が滞っていたのですが、2022年を振り返るといろいろあったのでここで振り返ろうと思います。なお、今年のそのいろいろは忘れたくない(あと感染症的にあえてやろうとも思わない)ので忘年会は0です。誘われてないわけじゃないんだからね。
Kaggle commpetition masterになった
1月に終わったpetfinderコンペで(チーム)金を取得し、そのあとjigsawコンペで(ソロ)銀を取得でき、始めた当初の目標であったkaggle masterになることができました。
kaggler同士交流するイベントで交流したきっかけであったり、それより前のコンペでチームを組んだきっかけなどがうまく積み重なって降ってきたものなので、まだまだ精進する必要があると感じています。
kaggle days championship でバルセロナに行った
マスターになってから予選に参加し始めて、4月の東京予選で優勝しバルセロナの権利を獲得しました。 kaggleでできた人脈や、masterという威光でチームに入れてもらったと思っています。
予選本番のコンペに関してはバルセロナ行きを決めたコンペではたまたま当たりデータを担当できましたが、本番ではパイプラインが動かなかったりでほぼ貢献できず個人としてとても悔しい結果で終わってしまいました。
余談ですが、出国から帰国までの9日間チームメンバー4人で過ごしました。私視点1回顔合わせ(飲み会)して2回目の対面のメンバーだったのですがずっと楽しく帰国まで旅行ができたのって結構幸運なことだったと今でも振り返って思います。この場を借りて改めてありがとう。
ふりかえると
今年は2020年、2021年と取り組んだkaggleを通してできた人脈があったからこそできた体験がかなり多かった1年だと思います。最近はちょっと他の勉強をしていますがそれを2023年中に終わらせてまた機械学習コンペに取り組むことを2023年の目標とします。
『推薦システム実践入門』の写経で躓いた所メモ
こんにちは
『推薦システム実践入門』を写経していて本の通り動かない部分があったため、メモとして残します。
今回は5章のIMFでimplicitを使う部分
各ライブラリのバージョン
numpy:1.21.6 implicit:0.5.2 scipy:1.7.3
リンク
本題
本のコード
# モデルの初期化 model = implicit.als.AlternatingLeastSquares( factors=factors, iterations=n_epochs, calculate_training_loss=True, random_state=1 ) # 学習 model.fit(movielens_matrix) # 推薦 recommendations = model.recommend_all(movielens_matrix.T) >>> Precision@K=0.026, Recall@K=0.080
出典:風間正弘、飯塚洸二郎、松村優也著『推薦システム実践入門』(オライリー・ジャパン、ISBN978-4-87311-966-3)
自分の環境で動かすと
recommendations = model.recommend_all(movielens_matrix.T)の所でuser_items needs to be a CSR sparse matrixというエラーが出ます。
ただ、エラーの言うように.tocsr()しても治らない。コレについてはfitとrecommendで片方だけ.Tしていることが原因っぽいです。
どちらに合わせるかというところですが、implicitの実装を見てみると、"A sparse CSR matrix of shape (number_of_users, number_of_items)."と記載があるため下記のように.T.tocsr()することで本の通りの出力になった。
# 学習 model.fit(movielens_matrix.T.tocsr()) # 推薦 recommendations = model.recommend_all(movielens_matrix.T.tocsr()) >>> Precision@K=0.026, Recall@K=0.080
lil_matrixを用意して値を入れていく段階で行方向をユーザーにするように変更するほうがスマートとは思います。
また躓いたら追記します。
それでは。
ヨーロッパ旅行記⑧[プラハ観光2]
はじめに
この旅行記は昔したヨーロッパ旅行の記録です。
1週間ほどかけてドイツ、チェコ、オーストリアを周遊しました。
できる限り自分が見たい旅行記に近づけるようにがんばって書いています。
ここが良い、これがほしいありましたらご意見待ってます。
バックナンバー
ヨーロッパ旅行記②[フランクフルト~ローテンブルク~フュッセン]
ヨーロッパ旅行記③[ノイシュバンシュタイン城~フュッセン市街地]
今回の旅程
お久しぶりです、気がついたら前回の更新から16ヶ月たっていました。
前回はアパルトメントから旧市街を抜けてプラハ城まで移動して観光をしたところまででした。今回はプラハ城からまた観光しながらプラハ駅の方まで移動をします。

プラハ城を出るとちょうど衛兵交代式が行われていました



これはちょっと何かはわからないです

チェス盤がおいてあったので1枚。もう少し後ろの町並みのぼかしが弱くてもいい気がする

お昼ごはん
プラハ城から歩いて坂を降りていい感じにビールが飲めそうなごはん屋さんに入ります

同行者がレシートも撮ってたのでどこにいったかわかりました笑

私が頼んだのはこちら。英語メニューを読んで注文したのですが前日チェスキークロムロフで食べたものと全く同じものが出てきた衝撃は忘れません。
違うのが食べたかった。美味しいというよりこの白いパン(クネドリーキ)は1色で飽きていた・・・

同行者視点
カレル橋を渡って旧市街の方に移動します。
カレル橋とその周辺にはたくさんのパフォーマーがいたりウィンドウショッピングできそうな店も並んでいてにぎやかです

数いるパフォーマーの中でもこれはよく分からなくてお金入れちゃいました。
今思えば上下のそれぞれの左腕あたりがポイントではありそうですね

カレル橋からの風景
旧市庁舎にのぼります

何故か外観の写真はないです。
以下、時計塔からの風景






ここまで屋根の高さと色が揃っている景色もなかなかないかもしれないですね。
外壁は自由度高くてそれもきれいな気がします。
この後ウィーンへの移動が控えているので駅に歩いていきます。





こんな電車に乗りました

ウィーン駅
残りウィーンの観光して終わりです。
こんかいはここまで!
【Kaggle挑戦記】AI4Code振り返り【#15】

こんにちは
先日終了したkaggleのAI4Codeに参加してました。
やったことのないタスクだったためアプローチなどを知るために参加しました。少しでも自分のアイデアを使ったサブができたら良かったのですがローカルでスコアの再現が全く取れなかったりだらけきってしまったことにより、公開ノートのサブをする程度で終わってしまいました。
今回は自分が見た範囲のアプローチをメモとして残して、コンペ中うまくいかなかった部分を最後にちょこっとかきます。
コンペ内容
- kaggle notebookに公開されてるノートのセルの正しい並び順を予測する
- 正しい順序に並んでるCodeセルのどの位置にmarkdownセルが入るかを予測する
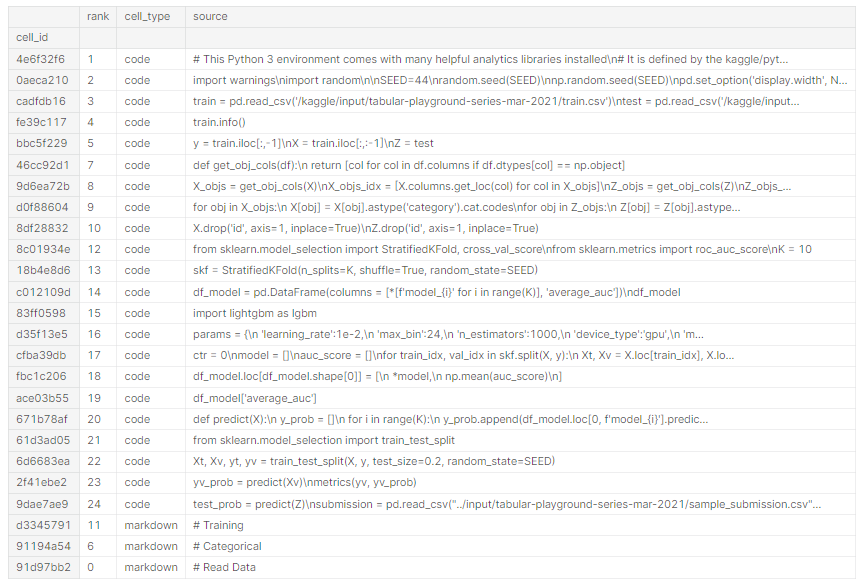
このように24個セルあるノートのデータは21個のcodeセルが上に順序どおり並んでおり、markdownセルは順不同で下に3つ並んでいるデータになります。trainデータは順序が与えられているためこのようにrankを付与できる。
アプローチ
1.GBDTのrankモデル
- hostsがチュートリアルとして公開してくれたもの
- TF-IDFでベクトル化してXGBRankerで学習する
2.BERTモデルで回帰タスクとして解く(markdownデータのみ)
- rankを[0:1]で正規化して回帰として解く
- markdownの情報だけで学習
このテキストは全体のうちどのくらいの位置にあるかを予測します。問題を既に知ってる別の問題に置き換えて?学習するアプローチの仕方で私はこの方法が好きです。
3.BERTモデルで回帰タスクとして解く2(code情報も使用)
- 多分本コンペでの神カーネルはこれ
- 上のモデルはmarkdown情報だけを用いてるためcodeセルの情報も使えば精度が上がることは明らか
- ここのカーネルではcodeの情報を部分的に使用してモデルに入力している
- [SEP] Markdown content [SEP] Code content 1 [SEP] Code content 2 [SEP] ... [SEP] Code content 20 [SEP]
- 0.7534から0.84くらいまでスコアが上がる
- 0.7534は少量データで1エポック、0.84は全データで3epochなのでちょっと条件は違う
4.Pairwiseでどこのコードに隣接してるか学習する
- 入力データは[CLS] + markdown + [SEP] + code + [SEP]
- ラベルはmarkdownとcodeが隣接していれば1,してなければ0として学習する
- 推論時間は長くかかる
- 0.8171くらい
以上がコンペ期間中に私が確認したアプローチです。まだpublic上位の解放を確認してないのでこれから勉強しようと思います。
うまくいかなかった話
ローカルでスコアが出なかった
今回、2や3をローカルでpytorch lightningのコードとして実装し直して実験しましたが、2は0.65程度、3も0.635程度しかスコア出ず、公開ノートの再現すら全くできない状態でした。
本コンペはcv/publicの相関は比較的とれており、この低スコアのCVはpublicも低くただ学習がうまくできてない状態です。学習率やスケジューリングの誤差でここまで悪化するようにも思えず結局最後まで何が原因かわかりませんでした。なにか心当たりがあればtwitterでこっそり教えてほしいです(涙
ハイブリッドモデルができなかった
3はmarkdownもcodeも同じモデルに入力しているのですが、別々のモデルを使えないかと考えました
図にするとこんな感じ
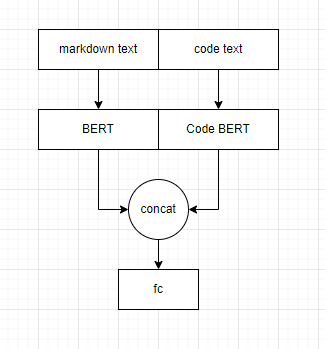
コードだとこんな感じ
class HybridModel(nn.Module): def __init__(self, cfg): super(HybridModel, self).__init__() self.cfg = cfg self.code_model_name = 'microsoft/codebert-base' self.mark_model_name = 'distilbert-base-uncased' self.code_config = AutoConfig.from_pretrained(self.code_model_name, output_hidden_states=True) self.mark_config = AutoConfig.from_pretrained(self.mark_model_name, output_hidden_states=True) self.code_model = AutoModel.from_pretrained(self.code_model_name, config=self.code_config) self.mark_model = AutoModel.from_pretrained(self.mark_model_name, config=self.mark_config) self.fc = nn.Linear(self.code_config.hidden_size + self.mark_config.hidden_size, 1) def forward(self, ids, mask): mark_ids = ids[:self.cfg.md_max_len] mark_mask = mask[:self.cfg.md_max_len] code_ids = ids[self.cfg.md_max_len:] code_mask = mask[self.cfg.md_max_len:] code_outputs = self.code_model(code_ids, code_mask)[0] mark_outputs = self.mark_model(mark_ids, mark_mask)[0] outputs = self.fc(torch.cat((code_outputs[:,0,:], mark_outputs[:,0,:]),1)) return outputs
これは普通にインスタンスを作って1バッチぶんいれたら動くけど、lightningで動かそうとするとエラーが出て直せませんでした。
RuntimeError: CUDA error: device-side assert triggered
このあたりも残課題として調べていこうと思います;;
機械学習コンペ(テーブルデータ)をする時の特徴量管理を考える #1

kaggleなどでのテーブルコンペの公開ノートブックではそのノートですべてを完結させるという意味でもノート内で特徴量を作成していることが多いです。
しかし、長期間のコンペになると実験数は増えるし、処理に時間がかかる特徴量を使うケースも増えてきます。実験のたびに特徴量を計算するのは地球にやさしくない。。。
この問題に対するシンプルな対策は作った特徴量をファイルで保存しておいて読み取るだけにすることだと思います。
具体的な方法は kaggle 特徴量 管理 でググれば素晴らしい記事がいくつも出て来ると思います。
今回は特徴量毎に数値特徴量かカテゴリ特徴量かの情報も欲しくなったのでその情報も一緒に管理できるようにしていたのでその管理方法を紹介したいと思います。
そのまま誰かの役に立てば幸いですし、何かフィードバックが得られれば嬉しいです。
内容
- trainの特徴量、testの特徴量、数値特徴量名、カテゴリ特徴量名をdictionaryに入れて保存
- あまりにもデータが多い時は容量の無駄になるが、mergeでなくconcatで繋げる想定
- reset_indexしておかないとconcatで行数が増えてバグるから注意(何回かやった
特徴量を作るとき
例えば特徴量を作るときはこのように作って保存
import umap def get_train_test(): _train = pd.read_csv(INPUT_DIR / "train.csv") _test = pd.read_csv(INPUT_DIR / "test.csv") return _train, _test def save_pickle(filename, obj): with open(filename, mode='wb') as f: pickle.dump(obj, f) n_dim = 6 df_train, df_test = get_train_test() len_train, len_test = len(df_train), len(df_test) df = pd.concat([df_train,df_test]) cont_cols = [col for col in df_train.columns if pd.api.types.is_numeric_dtype(df_train[col])] for col in ['id','pm25_mid']: cont_cols.remove(col) # 次元削減する mapper = umap.UMAP(n_components=n_dim, random_state=29) x_embedded = mapper.fit_transform(df[cont_cols]) df = pd.DataFrame(x_embedded).add_prefix('UMAP') # 戻す df_train = df[:len_train] df_test = df[len_train:] # 保存 COL_UMAP = df.columns.to_list() d = dict(train=df_train[COL_UMAP],test=df_test[COL_UMAP],cate_cols=[],cont_cols=COL_UMAP) save_pickle(FEAT_DIR / 'UMAP.pkl', d)
読み込むとき
読み込むときはfeatsの中に使う特徴量を羅列していく
# 使う特徴を並べる feats = [ 'OE', 'Country_TE', 'near_city1', # 'min_max_diff', 'near1_City_LE', 'UMAP', ] for f in feats: d = load_pickle(FEAT_DIR / f"{f}.pkl") df_train = pd.concat([df_train, d["train"].reset_index(drop=True)],axis=1) df_test = pd.concat([df_test, d["test"].reset_index(drop=True)],axis=1) CFG.cate_cols += d["cate_cols"] CFG.cont_cols += d["cont_cols"] print(f'Load... {f} , {len(d["cate_cols"])+len(d["cont_cols"])}features') print(f'{len(CFG.cate_cols)}cate_cols, {len(CFG.cont_cols)}cont_cols') CFG.feature_cols = CFG.cont_cols.copy() + CFG.cate_cols.copy()
LightGBM
- エンコードさえしてあれば数値型のままでも入力できるので特別にすることはなし
- カテゴリ変数を明示的にmodelに伝えるもよし伝えないも良しで検証している記事があります
Catboost
- カテゴリ変数をstringにする必要がある
df_train[CFG.cate_cols] = df_train[CFG.cate_cols].astype(str)
- Poolを作るときにカテゴリ変数を指定する
Pool(df_test[CFG.feature_cols],cat_features=CFG.cate_cols)
XGBoost
- 特になし
DNN
for col in tqdm(CFG.cont_cols): qt = QuantileTransformer(random_state=0, output_distribution='normal') df_train.loc[:,col] = qt.fit_transform(df_train[[col]].to_numpy()) df_test.loc[:,col] = qt.transform(df_test[[col]].to_numpy())
- 埋め込み表現のボキャブラリ数を取るとき
CFG.n_categories = [] for cat in CFG.cate_cols: # CFG.n_categories.append(pd.concat([df_train,df_test])[cat].nunique()+1) CFG.n_categories.append(int(pd.concat([df_train,df_test])[cat].max()+1))
- Datasetを作るとき(Pytorch
TabularDataset(x_num = self._df_train[self._cfg.cont_cols].to_numpy(),
x_cat = self._df_train[self._cfg.cate_cols].to_numpy(),
y = self._df_train[[self._cfg.target_col]].to_numpy(),)
課題
拙いコードだと思いますがここまでご覧いただきありがとうございます。この方法はtestデータが手元にない場合には使えません。あらかじめtrainでfitさせたものの用意とかもっと別の形のものがあると思います。
ということで課題や改善余地を残して#1として今回はここまでとします。
大気中の汚染物質濃度の予測に挑戦しよう!に参加してきました

SIGNATEで開催されていたソニーグループ合同 データ分析コンペティション(for Recruiting)に参加してきました。
結果は835人中84位で上位10%くらいでしょうか。20位までsony製品の賞品が出るコンペだったので商品に手が届かず悔しいです。
内容
待機観測データ等を用いてpm25の値を予測するコンペです。細かい概要とデータについてはコンペサイトに記載されています。
trainとtestは都市ごとに分かれていること、3年分だが計測に欠損はたくさんある(1000日分くらいデータが有る都市もあれば殆どない都市もある)ことが特徴に思いました
取り組みと解法
前処理
- Trainから測定してるけど0のデータの削除
CV
- TestはTrainに無い都市のためCity毎でFold
特徴量
- 数値特徴量が多かったので機械的に特徴量を増やさず意味の有りそうなものを作成
- 国と年、月などを組み合わせたカテゴリー作成
- 近傍都市情報
- lagやdiff
- 集約やターゲットエンコード
- 国+年月のターゲットエンコーディングや、近傍都市のターゲット情報は特に有効だった
モデル
- 序盤はLightGBMシングルで特徴量作成メイン
- 最終的にLGBM,XGB,catboost、MLP,1DCNNの5種類を使用
- Deepモデルは欠損は補完しなければいけなくlagや近傍とし情報は欠損が多いためmeanで補完するだけではGBDTよりもスコアで劣った。
- ただし有効な特徴量の傾向が少し違い、1DCNNはとくにGBDTモデルとアンサンブルが効いた。
stacking
- ある程度有効だった
- 都市関係なくKFoldで学習
全データで学習
- どんなSeedでFoldをきってもscoreが悪いFoldがあった(=予測が難しい都市がある)
- 全データで学習するとCVはわからなくなるがLBは向上した。
- もともとCVとLBの相関はある程度取れていたためLBが改善するならいいやと判断した
失敗談
- ずっとラベルを対数とっていたが対数撮るのをやめたらスコアがかなり良くなった。
- 特に制度が悪いインド中国にとっかしていい制度が出るモデルを作ろうと思ったがダメだった
解法図

train on all data部分のアンサンブルでpublic20.695147くらい。スタッキングを合わせてpublic20.6833303
感想
今回の他の参加者のソリューションを見るとまだまだ特徴量でどうにかできたみたいです。ポツポツとモデルを改善できる特徴量は作れていましたがまだまだ足りなかったということで少し追加で実験してみようと思います。題材に関してもせっかくだからpm2.5についてもう少し勉強していい特徴量を作ってみたかったと公開しています。
また、今回参加した理由は商品もありますがテーブルデータのコード遺産を増やすという目標がありました。現状散らかった状態ですがそれなりに色々実装したのこっち進捗はあったので整理して今後のコンペに活用していけるようにしたいと思います。
また次のコンペ頑張ります!
Kaggle Days Championship Tokyo で優勝しました!

こんにちは
先日行われた Kaggle Days Championship Tokyoに参加してきました。
参加はyukiさん、kutoさん、sqrt4kaidoさんとの4人チームです。
結果は83チーム中で優勝することができました。
おそらくこれでバルセロナのFINALイベントに参加できることになると思います。スペインは行ったことのない国でとても楽しみです。(無事現地に行けたらいいな
ちょっとタスクに触れる
ソリューションはコチラに、私が使ったノートはコチラに公開されています。
今回のタスクはD1からD10のそれぞれ内容が異なるデータテーブルが与えられ、そのテーブル内の欠損値を埋めるというものでした。
所謂imputingというタスクで sklearn にも KNNImputer というものが用意されているみたいです。今回のコンペが終わってから知りました。
csvが10個と見なきゃいけないデータが10種類なので、モデル数も多くなることが想定され4人で分担して進めました。この進め方に関しては後から他チームの公開したノートを見ると10個のデータすべてに対して動くパイプラインを作るという進め方がありました。
何れにせよまだこの4時間コンペ3回目ですがデータ見る時間がたりなさすぎでは?と言うのはちょっと気になりました。
さて、私の担当はD3で、まずはA列を予測するLightGBMベースラインを作成しました。作ったところ精度が芳しくなくかなり焦りました。
A列を見てみると1行目から最後の行まで値が上昇し続けていたためこの列に関しては前後の値を使ってfillすることに決定。同時にほかのカラムについて調べるとsortされてはいなさそうだったのでそのままLightGBMで予測しました。(B列以降はscoreもよさそうだったので一安心。
カテゴリ列はかなりの不均衡だったので予測でなく頻度の高いほうで埋めるだけにしました。ここまでで時間は少なくなってたので残りの時間でできるだけD9を学習/予測しました。
提出は各々予測したものをベースラインに組み込んでどれくらいスコアが変わるか観察という感じでした。
今回は分担しましたが一つのデータに対してあれこれ議論しながら進めるコンペが楽しみです!
おわりに
最近やっと準備したテーブルデータに対するLightGBMのパイプラインがあったおかげで比較的サクサク進みましたが、それでも各所でコードは調べながらやっていました。調べる回数が減らせるようにもっと頑張っていきたいです。
まだKaggle Days Championship は何回かあるのでできるだけ参加していい成績をとれるように頑張ります!