
こんにちは
最近PyTorch Lightningで学習をし始めてcallbackなどの活用で任意の時点でのチェックポイントを保存できるようになりました。
save_weights_only=Trueと設定したの今まで通りpure pythonで学習済み重みをLoadして推論できると思っていたのですが、どうもその認識はあっていなかったようで苦労しました。今回は学習済みの重みで予測するところまで進めようと思います。
※ちなみにsave_weights_onlyのTrueとFalseは全く違う設定のようです
結論
結論としては下記の2つの方法ができそうだなと思いました。
- 学習時の
LightningModuleのインスタンスを作ってload_from_checkpointで読み込む - 学習が終わったら
torch.save(model.model.state_dict(), outpath)で保存する
まずは保存
保存の手順についても軽く触れておきます。
まずはModelCheckpointのインスタンスを作ります。
loss_checkpoint = ModelCheckpoint(
dirpath=OUTPUT_DIR,
filename=f"best_loss_fold{fold}",
monitor="val_loss",
save_last=True,
save_top_k=1,
save_weights_only=True,
mode="min",
)
auc_checkpoint = ModelCheckpoint(
dirpath=OUTPUT_DIR,
filename=f"best_auc_fold{fold}",
monitor="val_score",
save_top_k=1,
save_weights_only=True,
mode="max",
)
あとはTrainerに渡して学習するだけ。
trainer = pl.Trainer(
logger=wandb_logger,
callbacks=[loss_checkpoint, auc_checkpoint, lr_monitor],
default_root_dir=OUTPUT_DIR,
gpus=1,
progress_bar_refresh_rate=1,
accumulate_grad_batches=CFG.grad_acc,
max_epochs=CFG.epochs,
precision=CFG.precision,
benchmark=False,
deterministic=True,
)
model = Trainer(CFG)
trainer.fit(model, data_module)

指定したフォルダに2つのModelCheckpoint分のチェックポイントと、lastの計3つのチェックポイントが生成されます。このckptファイルを使って推論をできるようにします。
もちろん公式にチェックポイントの保存と読み取りに関するドキュメントは用意されています。
チェックポイントを読み込んで推論する
とりあえずチェックポイントをtorch.load()で読み込んで中身を見る。
checkpoint = "../input/hoge/best_loss_fold0.ckpt"
state_dict = torch.load(checkpoint)
state_dict
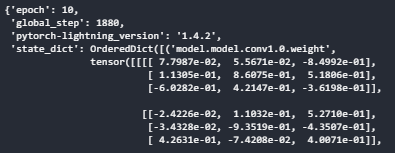
state_dictに重みが入っていそう。
state_dict.keys() >> dict_keys(['epoch', 'global_step', 'pytorch-lightning_version', 'state_dict'])
キー一覧を見ると、state_dict以外にも3つ項目が含まれていることがわかります。
state_dict["state_dict"]でload_state_dict()したらいけそう?
timmで同じ構成のmodelをつくって読み込みます。
checkpoint = "../input/hoge/best_loss_fold0.ckpt" device = torch.device("cuda" if torch.cuda.is_available() else "cpu") model = get_model(CFG) model.to(device) model.eval() state_dict = torch.load(checkpoint, map_location=device) model.load_state_dict(state_dict["state_dict"])

とても怒られた(´・ω・`)
ググって参考な記事を見つけたので試してみます。 + PyTorch LightningのckptファイルをLoadするのにはまった話 + PyTorch LightningのckptファイルをLoadするのにはまった話のその後
strict=Falseってやつをやってみる。
model.load_state_dict(state_dict["state_dict"],strict=False)

エラーは出ませんが互換性がないキーが大量に出てきます
load_state_dict()前後で値も変わっていないのでちょっとダメそう。ヤンチャすぎましたか。
model = get_model(CFG) print(model.state_dict()['model.conv1.0.weight'][0]) model.to(device) model.eval() state_dict = torch.load(checkpoint, map_location=device) model.load_state_dict(state_dict["state_dict"],strict=False) print(model.state_dict()['model.conv1.0.weight'][0]) >> tensor([[[-0.0417, 0.0072, -0.1121], [ 0.1637, -0.0598, -0.0470], [ 0.0556, 0.1053, -0.0689]], [[-0.0978, -0.0325, -0.1222], [-0.0573, 0.0169, 0.1032], [-0.0287, -0.0851, -0.0106]], [[ 0.0569, 0.0524, 0.0678], [-0.0426, -0.0429, 0.0857], [-0.0206, 0.0479, 0.1518]]]) tensor([[[-0.0417, 0.0072, -0.1121], [ 0.1637, -0.0598, -0.0470], [ 0.0556, 0.1053, -0.0689]], [[-0.0978, -0.0325, -0.1222], [-0.0573, 0.0169, 0.1032], [-0.0287, -0.0851, -0.0106]], [[ 0.0569, 0.0524, 0.0678], [-0.0426, -0.0429, 0.0857], [-0.0206, 0.0479, 0.1518]]], device='cuda:0')
諦めてLightningModule.load_from_checkpoint()する
ヤンチャしないで諦めてLightningModule宣言してload_from_checkpointでチェックポイントを読み込みます
model = Trainer(CFG) checkpoint = "../input/hoge/best_loss_fold0.ckpt" model = model.load_from_checkpoint(checkpoint) >> __init__() missing 1 required positional argument: 'cfg'
が、cfgがないと怒られます。
それならとcfgを引数に入れたら出来ました。
CKPT_PATH = "../input/glrmodel/best_loss_fold0.ckpt" print("保存されてるweights") state_dict = torch.load(CKPT_PATH) print(state_dict["state_dict"]['model.model.conv1.0.weight'][0][0]) model = Trainer(CFG) print("モデル宣言時のweights") print(model.model.state_dict()['model.conv1.0.weight'][0][0]) model = model.load_from_checkpoint(checkpoint_path=CKPT_PATH,cfg=CFG) print("checkpointロード後のweights") print(model.model.state_dict()['model.conv1.0.weight'][0][0]) >> 保存されてるweights tensor([[ 0.0780, 0.0557, -0.8499], [ 0.1131, 0.8607, 0.5181], [-0.6028, 0.4215, -0.3620]], device='cuda:0') モデル宣言時のweights tensor([[-0.1406, 0.0140, -0.1002], [-0.1681, 0.1721, -0.0279], [-0.0425, -0.1278, 0.1192]]) checkpointロード後のweights tensor([[ 0.0780, 0.0557, -0.8499], [ 0.1131, 0.8607, 0.5181], [-0.6028, 0.4215, -0.3620]])
値がロードされていることも確認できました。
よく見るとチェックポイント内のウェイトはmodel.modelの中に入ってるんですね。ここを何とかするといろいろできるかもしれないです。
cfgが必要な理由としては私のLightningModuleが下記のようになっているためです。
class Trainer(pl.LightningModule): def __init__(self, cfg):
おまけ
とあるコンペのsolutionを読んでいて、最後にtorch.save(model.model.state_dict(), outpath)しているコードがあったので試してみました。
これで保存したものはmodel.load_state_dict(state_dict)でロードできました。ご参考までに。
model = Trainer(CFG) trainer.fit(model, data_module) torch.save(model.model.state_dict(),OUTPUT_DIR + '/' + f'{CFG.exp_name}_fold{fold}.pth')