※このページにはColeridgeコンペで良スコアを出す方法は書かれていません。初めて自然言語タスクに挑戦したのでその記録です。
概要
科学論文(英文)の中から、使用しているデータセットについて言及している箇所を抽出してくるというのが本コンペのタスク
- 論文内でTypoがあればTypoをそのまま抽出する
- 評価値はJaccard係数ベースのFBetaスコアで評価
- 9 Distance Measures in Data Scienceで見た名前だったのでちょっと嬉しかった
clean_textを通して文字列の規格をそろえて評価させる
python def clean_text(txt): return re.sub('[^A-Za-z0-9]+', ' ', str(txt).lower())train labelからマッチングで抽出してもいいprivateスコアにはならない
DiscussionやCodeから推察するにNLPの中でもNamed entity recognition (NER)タスクに当たる課題のようだが、お作法が全くわからないので周辺知識から1つづつ学んで最終的になにかサブミットをすることを目標に取り組む。
評価値
F0.5
- 分母のprecisionに0.25が乗算されるのが特徴(recallは等倍)

- 分母のprecisionに0.25が乗算されるのが特徴(recallは等倍)
FPのペナルティがが大きい
- Jaccard距離0.5以上の予測ラベルをTPにする
- Jaccard距離0.5以上だが、すでに他の予測ラベルと対になっているGroundTruthの場合その予測値はFP
- GroundTruthになかったらFP
- 予測できなかったらFN
つまり、予測し過ぎは大きいペナルティを受けやすい?
ポイント
本コンペのポイントの一つとしてラベルが挙げられます。trainラベルはpublicに使われるデータには含まれるが、privateには含まれないということがホストより明示されていました。
ホストが求めるソリューションは文字列照合ではなく統計的、機械学習的なソリューションで汎用的に利用できるものですが上記ことによりtrainラベルを使ったliteral matchingをするとpublicLBではスコアが高く見えるという事象が発生してたように思います。
参考
A percentage of the public test set publications are drawn from the training set
publicテストセットの出版物の一部は、トレーニングセットから抽出されています。(文字列マッチングで正解できるデータがpublicにある)
- testdata数が8000個(public960(traindataも一部あり),private7040)
基本的にBERTを使う雰囲気
NLPについてゼロから学びつつコンペにも取り組んでいく。まず公開ノートやディスカッションを眺めるとspaCyやBERTが使われていることがわかる。いい機会なのでBERTの使い方を本コンペでは学んでいくことにしました。
【解説記事】BERT解説:自然言語処理のための最先端言語モデル
- 記事によるとコンペ内で見られるMLMという単語はMasked Language Modelの略称でBERTの事前学習戦略の2つの内の1つがこのMLM
- もう一つはNSP(Next Sentence Prediction)という次文予測
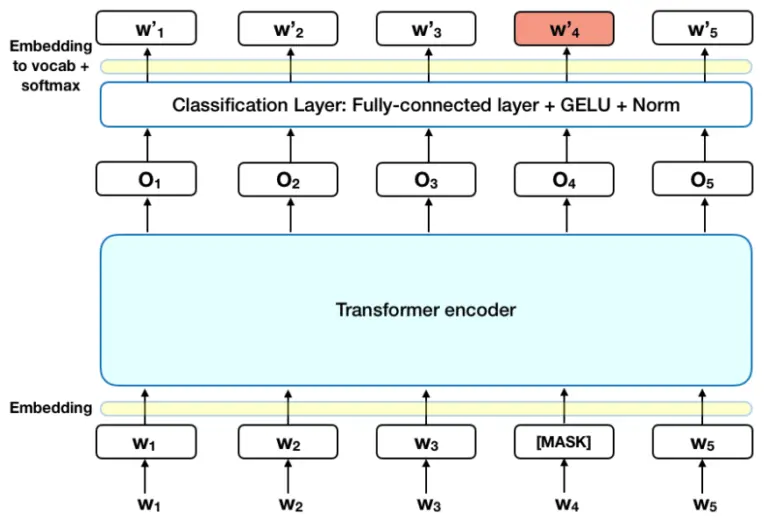
GELU(Gaussian Error Linear Units):活性化関数
BERTモデルの学習においては、マスクされたLMと次文予測というふたつの戦略に関する損失関数の結合が最小化するというゴールにむかって、このふたつの戦略がいっしょに学習される。
【PyTorch】BERTの使い方 - 日本語pre-trained modelsをfine tuningして分類問題を解く
FineTuningすることでセンチメント分析、QA、固有値解析(NER)等様々なタスクに適用可能
本コンペの情報ではQAとNERの文字を見かけるのでまずはNERについて見ていく。
BERTを使用する
BERTを使用するにはHugging Face の Transformersライブラリがデファクトスタンダードな様子。BERTなどの最先端のアルゴリズムを簡単に試すことができる。pytorch,tf対応。他のライブラリがあるのかまでは未調査。
- https://huggingface.co/transformers/
- インストール
pip install transformers
学習済みモデルを使って推測する
pipeline()を使うことでかんたんに各種タスクを実行できる
【参考サイト】【NLP】Hugging Faceの🤗Transformersことはじめ
finetuningして使う
コンペなどでしっかり精度を出していくにはタスクで与えられたデータを使ってfinetuningしていくことが必要になる。
学習方法は下記のような選択肢があるっぽい
MLM
学習note [Coleridge] BERT - Masked Dataset Modeling
予測note [Coleridge] Predict with Masked Dataset Modeling
- ほとんどのデータセット名は、頭文字が大文字の単語と、on, in, and などのストップワードで構成されている
- 大文字で書かれた単語をすべて探し、dataset名を表しているか、そうでないかを$と#でラベル付けし、MLMタスクで学習をする
NER
【Techの道も一歩から】第26回「BERTで日本語固有表現抽出器を作ってみた」
上記事のリンクが404になっているが、リポジトリのtoken-classificationのところにあるっぽい。学習したいテキストデータをBERTように整形(前処理)、label付けをしてからrun_ner.pyを叩いて学習をするということがわかる。
一連の流れがわかるとなんとなく公開ノートで行われてることもわかってくる。与えられてるのが、論文の文章とデータセット名を言及している部分(抜粋)なので、この情報をもとにlabeling(タグ付け)作業が必要になってくる。
タグについては【Techの道も一歩から】第34回「固有表現抽出のためのデータを作る」 R&D 連載にIOB2タグについて載っている。引用すると
学習を始めると吐き出されるWarning
- You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.(このモデルを予測や推論に使えるようにするには、ダウンストリームのタスクでトレーニングする必要があるでしょう。)
- 語彙辞書の作成やトークン化など”上流”タスクに対し、ニューラルネットワークを用いたモデル学習のことを”下流(downstream)”タスクと呼んでいるみたい。(引用)
が可能になります。最近、BERT、XLM、XLM-RoBERTa などの大規模な事前トレーニング済み言語モデルは、センテンス レベルのダウンストリーム タスクで微調整した場合に大きな成功を収めています。これらのクロスリンガル モデルを文書表現学習に適用することは魅力的です。ただし、次の 2 つの課題があ
— arXiv cs.CL 自動翻訳 (@arXiv_cs_CL_ja) 2021年6月8日
結果
公開ノートを参考にしながら複数モデルを組み合わせました。各モデルの予測をunionして、jaccardスコアをつかって重複してそうなラベルは削除しました。結果は散々ですが複数モデルの組み合わせで若干スコアはあげられてたみたいです笑



また、物は使いようではありますが、1stの意見ではBERT型のモデルを考えなしにつかうとtrain label(privateにはないと言われてる)にoverfittingするという話が印象的でした。 Coleridge Initiative - Show US the Data | Kaggle
The reason why GPT worked and Roberta failed so hard is that Roberta is too clever for its own good. When you try to build a text extraction model with a single query of finding dataset names, Roberta doesn't need to care about the context and will try to find a substring that most resemble a dataset name, thus lead to overfitting.
最後に
winner's solutionをちょこちょこと読んでますがわからない部分が多く、solutionで勉強になればと思ってたもののなかなか厳しそうです。
また次のコンペがんばります。
おまけ
今回はNotionでコンペの取り組みを管理してみました

本記事のドラフトはコチラです。 www.notion.so